It is me again - sorry. I have a problematic HD reallocating sectors. The counter just moved from 40 to 49. To set the data value to 0 again I entered an offset of -49. The next thing I got (almost immediately) was a reallocated sector count of 4294967295 (see attachment) I just did a panic backup and deleted all confidential data (even if they are encrypted anyway). The disk still has warranty and I will send it in for a replacement.
After all this I looked at other SMART software. AIDA64 and Crystal Disk Info both show me 48 as reallocated sector value. What is correct now? If the count is still 48 there was no need to delete all the data. The disk just loses some sectors every couple of days and this does not worry me so much (I have a very good backup strategy with history). But with suddenly 4294967295 reallocated sectors on this disk in my RAID 0 array there is no tomorrow what makes a very big difference.
The health report says:
There are 65535 bad sectors on the disk surface. The contents of these sectors were moved to the spare area.
Why do I have there 65535 bad sectors and in the SMART overview 4294967295? I did not change any display settings and before I had 49 displayed.
And what is missing in the Health Report is that today the disk reported the first Uncorrectable Errors at the same time with some? new Reallocated Sectors. When I look at BOTH changes this makes me worried. The software does not care about this. It just focuses on the reallocated sectors. But I guess both changes in combination are very worrisome. Or do I see this wrong?
HDS 4.40 Wrong Data?
HDS 4.40 Wrong Data?
- Attachments
-
- Health.png (12.92 KiB) Viewed 27532 times
-
- Relocated Sektors Wrong.png (25.55 KiB) Viewed 27532 times
-
hdsentinel

- Site Admin
- Posts: 3175
- Joined: 2008.07.27. 17:00
- Location: Hungary
- Contact:
Re: HDS 4.40 Wrong Data?
> It is me again - sorry. I have a problematic HD reallocating sectors.
> The counter just moved from 40 to 49. To set the data value to 0 again I entered an offset of -49.
Thanks, yes, this is absolutely correct.
> The next thing I got (almost immediately) was a reallocated sector count of 4294967295 (see attachment)
> I just did a panic backup and deleted all confidential data (even if they are encrypted anyway).
> The disk still has warranty and I will send it in for a replacement.
This seems very interesting. The value you sent is general a "-1" value, so it seems there was an underflow condition happened: the counter decreased below zero.
There's a protection in Hard Disk Sentinel which does not really allow this - so I'm not sure how it is possible on your system.
Can you please use Report -> Send test report to developer now, after selecting the appropriate hard disk?
> After all this I looked at other SMART software. AIDA64 and Crystal Disk Info both show me 48 as reallocated sector value.
Of course the hard disk has 48 reallocated sectors. This is properly reported in Hard Disk Sentinel if you clear the offset (re-set to 0).
The configured offset in Hard Disk Sentinel modifies this readout (by the value you specified) but as you can see, other software does not allow specifying such offsets (to clear reported problems, if you tested the drive, to make sure it's perfect and you want to be notified about new problems only).
As you set -49, the counter should remain at zero, but somehow on your system it could go below zero, causing an underflow, so a very high number is displayed. This should never happen in normal situations, so the Report -> Send test report to developer option may help to check what happened on your system, as now there should be 0 problems reported, as you cleared the error-counter by the specified offset.
> The health report says:
> There are 65535 bad sectors on the disk surface. The contents of these sectors were moved to the spare area.
Yes, this is also the result of this under-flow situation. I'm so curious to check how it's possible on your system.
> Why do I have there 65535 bad sectors and in the SMART overview 4294967295? I did not change any display settings and before I had 49 displayed.
Because you selected to display decimal values after right click on the S.M.A.R.T. page.
In decimal format, the values may be sometimes confusing, as some S.M.A.R.T. attributes have different meanings in their high / middle / low word.
While in original, hexadecimal format, the displayed FFFFFFFF value may immediately give some information immediately, the decimal 4294967295 value (or its low word part, 65535) may cause confusion.
> And what is missing in the Health Report is that today the disk reported the first Uncorrectable Errors at the same
> time with some? new Reallocated Sectors. When I look at BOTH changes this makes me worried.
> The software does not care about this. It just focuses on the reallocated sectors.
> But I guess both changes in combination are very worrisome. Or do I see this wrong?
Excuse me, I'm not really sure I understand correctly.
I can make sure that Hard Disk Sentinel checks and reports BOTH the change of "Reallocated sectors count" and "Uncorrectable sectors count" attribute (and other attributes of course). And yes, exactly as you wrote, if two or more different problems reported (for example these) then yes, the combination of the problems are more than worrisome. This is exactly why the displayed health % and the text description also displays both problems.
This is described in Help -> Appendix -> Health calculation ("It should count the relationship between attributes. More different problems should decrease the result much drastically than only one single problematic attribute.")
> The counter just moved from 40 to 49. To set the data value to 0 again I entered an offset of -49.
Thanks, yes, this is absolutely correct.
> The next thing I got (almost immediately) was a reallocated sector count of 4294967295 (see attachment)
> I just did a panic backup and deleted all confidential data (even if they are encrypted anyway).
> The disk still has warranty and I will send it in for a replacement.
This seems very interesting. The value you sent is general a "-1" value, so it seems there was an underflow condition happened: the counter decreased below zero.
There's a protection in Hard Disk Sentinel which does not really allow this - so I'm not sure how it is possible on your system.
Can you please use Report -> Send test report to developer now, after selecting the appropriate hard disk?
> After all this I looked at other SMART software. AIDA64 and Crystal Disk Info both show me 48 as reallocated sector value.
Of course the hard disk has 48 reallocated sectors. This is properly reported in Hard Disk Sentinel if you clear the offset (re-set to 0).
The configured offset in Hard Disk Sentinel modifies this readout (by the value you specified) but as you can see, other software does not allow specifying such offsets (to clear reported problems, if you tested the drive, to make sure it's perfect and you want to be notified about new problems only).
As you set -49, the counter should remain at zero, but somehow on your system it could go below zero, causing an underflow, so a very high number is displayed. This should never happen in normal situations, so the Report -> Send test report to developer option may help to check what happened on your system, as now there should be 0 problems reported, as you cleared the error-counter by the specified offset.
> The health report says:
> There are 65535 bad sectors on the disk surface. The contents of these sectors were moved to the spare area.
Yes, this is also the result of this under-flow situation. I'm so curious to check how it's possible on your system.
> Why do I have there 65535 bad sectors and in the SMART overview 4294967295? I did not change any display settings and before I had 49 displayed.
Because you selected to display decimal values after right click on the S.M.A.R.T. page.
In decimal format, the values may be sometimes confusing, as some S.M.A.R.T. attributes have different meanings in their high / middle / low word.
While in original, hexadecimal format, the displayed FFFFFFFF value may immediately give some information immediately, the decimal 4294967295 value (or its low word part, 65535) may cause confusion.
> And what is missing in the Health Report is that today the disk reported the first Uncorrectable Errors at the same
> time with some? new Reallocated Sectors. When I look at BOTH changes this makes me worried.
> The software does not care about this. It just focuses on the reallocated sectors.
> But I guess both changes in combination are very worrisome. Or do I see this wrong?
Excuse me, I'm not really sure I understand correctly.
I can make sure that Hard Disk Sentinel checks and reports BOTH the change of "Reallocated sectors count" and "Uncorrectable sectors count" attribute (and other attributes of course). And yes, exactly as you wrote, if two or more different problems reported (for example these) then yes, the combination of the problems are more than worrisome. This is exactly why the displayed health % and the text description also displays both problems.
This is described in Help -> Appendix -> Health calculation ("It should count the relationship between attributes. More different problems should decrease the result much drastically than only one single problematic attribute.")
Re: HDS 4.40 Wrong Data?
Not may cause confusion. It does cause confusion.hdsentinel wrote:In decimal format, the values may be sometimes confusing, as some S.M.A.R.T. attributes have different meanings in their high / middle / low word.
While in original, hexadecimal format, the displayed FFFFFFFF value may immediately give some information immediately, the decimal 4294967295 value (or its low word part, 65535) may cause confusion.
This system is just Windows 7 32 Bit Ultimate with all updates and with many mostly modern Seagate disks. Nothing special. The only value I can change is the offset at least to my best knowledge. All other data are created by HDS only I guess.hdsentinel wrote:This seems very interesting. The value you sent is general a "-1" value, so it seems there was an underflow condition happened: the counter decreased below zero. There's a protection in Hard Disk Sentinel which does not really allow this - so I'm not sure how it is possible on your system.
As you can see at the attachment before the health report shows only 1 problem and does not care about Uncorrectable Errors - at least at the latest version 4.40. It will show several errors but only if the values with the green circle on the left show a problem. It will not care for any other values. For this reason I asked for a feature that the user can select values that are important to him and should be checked by HDS (just a further column next to the offsets for instance where I can set this).Stubi wrote:Excuse me, I'm not really sure I understand correctly.
I can make sure that Hard Disk Sentinel checks and reports BOTH the change of "Reallocated sectors count" and "Uncorrectable sectors count" attribute (and other attributes of course). And yes, exactly as you wrote, if two or more different problems reported (for example these) then yes, the combination of the problems are more than worrisome. This is exactly why the displayed health % and the text description also displays both problems.
I wrote already that based on the (wrongly reported) high reallocated sector count I deleted many (confidential) data as long as there was time left to do so because I have warranty on this disk and I will send it back. But without these data it did not make sense to continue to use the system (my whole accounting was now gone for instance). And restoring a backup under such conditions did not make sense. So I destroyed the 3 x 1 TB RAID 0 array when I took out the problem disk (a typical bad RAID 0 experiencehdsentinel wrote:Can you please use Report -> Send test report to developer now, after selecting the appropriate hard disk?
A little more testing from my side:
When an error occurs:
Health + Tray Icon display an Error. Drive Display in Computer shows everything okay - what is wrong.
Now I start HDS new with the existing error:
Health + Tray Icon + Drive Display in Computer show error - what is correct.
Now I set an offset to take away the error - so no error for HDS anymore:
Health + Tray Icon display no error. Drive Display in Computer still shows an error - what is wrong again.
-
hdsentinel
- Site Admin
- Posts: 3175
- Joined: 2008.07.27. 17:00
- Location: Hungary
- Contact:
Re: HDS 4.40 Wrong Data?
> Not may cause confusion. It does cause confusion.
I completely agree. This is why hexadecimal display is preferred and this is the default setting.
> This system is just Windows 7 32 Bit Ultimate with all updates and with many mostly modern Seagate disks.
> Nothing special. The only value I can change is the offset at least to my best knowledge. All other data are created by HDS only I guess.
Yes I agree. Just when I tried to re-produce the issue you exeperienced, I could not.
When I set an offset value which is larger than the error-counter, the resulting value is 0000, without the under-flow you experienced.
This is why I asked to please use Report menu -> Send test report to developer option, as then I can check the actual situaiton and what (and how) could happen on your system.
> As you can see at the attachment before the health report shows only 1 problem and does not
> care about Uncorrectable Errors - at least at the latest version 4.40.
Sorry for the confusion, I thought you mean "Off-line Uncorrectable sector count". Now I see you mean the "Uncorrectable errors".
I can confirm yes, 1 such error is not reported. The reason is very simple: such errors are usually independent from the hard disk itself but (in most cases) related to other problems in the working environment, for example overclocking, data communication problems, cable/connection issues, general (eg. chipset) overheat and so.
This is why only only more "Uncorrectable errors" reported (the image you previously sent confirm this in your other post), when their count really indicates problems.
> It will show several errors but only if the values with the green circle on the left show a problem.
> It will not care for any other values.
I can confirm this is NOT TRUE of course.
The attributes (with green circle) are marked by critical by the manufacturers and also they significantly determine the hard disk health.
However, many other attributes can indicate problems and of course these are also examined and evaluated by Hard Disk Sentinel, reporting problems if the values _really_ indicate. This includes the attribute you mentioned and also several other attributes, which the manufacturers do not care about (eg. in other S.M.A.R.T. tools they would never indicate problems, even if their change may be important).
> For this reason I asked for a feature that the user can select values that are important to him and should be checked by HDS
> (just a further column next to the offsets for instance where I can set this).
I'm not really sure if this would be a good idea ... This may result in invalid / incorrect display of status.
To determine when a particular attribute should indicate errors, we investigated 10000's of hard disk reports, got accurate information from data recovery companies and so - by these it was possible to determine when these actual values may indicate real problems.
Usually this may require a combination of attributes and their change, so simply setting 1-2 numbers may not be useful.
> I wrote already that based on the (wrongly reported) high reallocated sector count I deleted many (confidential) data as
> long as there was time left to do so because I have warranty on this disk and I will send it back.
Yes I see. Just I thought when you had the opportunity to create the screenshots, it is possible also to use Report -> Send test report to developer option.
Sorry for that, I expected that you first perform a backup and then investigate the situation by the tests offered in Hard Disk Sentinel.
This is usually better way - as you may even get back a worse (repaired / refurbished) drive in terms of warranty than yours ...
Especially if the drive itself is not as bad as you'd feel, for example the "Uncorrectable error" is originally independent from the drive.
This is why Hard Disk Sentinel does not recommend warranty replacement until you tested the drive - which may even repair problems - but if not, you may ask for replacement.
> So I destroyed the 3 x 1 TB RAID 0 array when I took out the problem disk (a typical bad RAID 0 experience ).
).
 I'm a bit shocked that RAID 0 is used for storing important data ....
I'm a bit shocked that RAID 0 is used for storing important data ....
> So I cannot create this report anymore. For the next time I will be using a different emergency system (not RAID 0) until I can
> use the main system again when I receive the replacement disk.
Thanks, I'd be so curious to see. Even in the emergency system the report may help - as then I can check OS type / version, Hard Disk Sentinel version, driver version, hard disk model (of the other drive you still have, I suspect it is same model you had previously) etc... which may give ideas what could happen.
> When an error occurs:
> Health + Tray Icon display an Error. Drive Display in Computer shows everything okay - what is wrong.
I can make sure that if the health goes low, the logical drive icon(s) in the Computer reflects this (as soon as Windows updates the display).
> Health + Tray Icon + Drive Display in Computer show error - what is correct.
In some cases, Windows may not update the Drive icon in the Computer immediately, yes, this may require some time.
> Health + Tray Icon display no error. Drive Display in Computer still shows an error - what is wrong again.
Exactly as I wrote before. Windows may requires some more time and/or a manual refresh (F5) to show the changed status.
I completely agree. This is why hexadecimal display is preferred and this is the default setting.
> This system is just Windows 7 32 Bit Ultimate with all updates and with many mostly modern Seagate disks.
> Nothing special. The only value I can change is the offset at least to my best knowledge. All other data are created by HDS only I guess.
Yes I agree. Just when I tried to re-produce the issue you exeperienced, I could not.
When I set an offset value which is larger than the error-counter, the resulting value is 0000, without the under-flow you experienced.
This is why I asked to please use Report menu -> Send test report to developer option, as then I can check the actual situaiton and what (and how) could happen on your system.
> As you can see at the attachment before the health report shows only 1 problem and does not
> care about Uncorrectable Errors - at least at the latest version 4.40.
Sorry for the confusion, I thought you mean "Off-line Uncorrectable sector count". Now I see you mean the "Uncorrectable errors".
I can confirm yes, 1 such error is not reported. The reason is very simple: such errors are usually independent from the hard disk itself but (in most cases) related to other problems in the working environment, for example overclocking, data communication problems, cable/connection issues, general (eg. chipset) overheat and so.
This is why only only more "Uncorrectable errors" reported (the image you previously sent confirm this in your other post), when their count really indicates problems.
> It will show several errors but only if the values with the green circle on the left show a problem.
> It will not care for any other values.
I can confirm this is NOT TRUE of course.
The attributes (with green circle) are marked by critical by the manufacturers and also they significantly determine the hard disk health.
However, many other attributes can indicate problems and of course these are also examined and evaluated by Hard Disk Sentinel, reporting problems if the values _really_ indicate. This includes the attribute you mentioned and also several other attributes, which the manufacturers do not care about (eg. in other S.M.A.R.T. tools they would never indicate problems, even if their change may be important).
> For this reason I asked for a feature that the user can select values that are important to him and should be checked by HDS
> (just a further column next to the offsets for instance where I can set this).
I'm not really sure if this would be a good idea ... This may result in invalid / incorrect display of status.
To determine when a particular attribute should indicate errors, we investigated 10000's of hard disk reports, got accurate information from data recovery companies and so - by these it was possible to determine when these actual values may indicate real problems.
Usually this may require a combination of attributes and their change, so simply setting 1-2 numbers may not be useful.
> I wrote already that based on the (wrongly reported) high reallocated sector count I deleted many (confidential) data as
> long as there was time left to do so because I have warranty on this disk and I will send it back.
Yes I see. Just I thought when you had the opportunity to create the screenshots, it is possible also to use Report -> Send test report to developer option.
Sorry for that, I expected that you first perform a backup and then investigate the situation by the tests offered in Hard Disk Sentinel.
This is usually better way - as you may even get back a worse (repaired / refurbished) drive in terms of warranty than yours ...
Especially if the drive itself is not as bad as you'd feel, for example the "Uncorrectable error" is originally independent from the drive.
This is why Hard Disk Sentinel does not recommend warranty replacement until you tested the drive - which may even repair problems - but if not, you may ask for replacement.
> So I destroyed the 3 x 1 TB RAID 0 array when I took out the problem disk (a typical bad RAID 0 experience
> So I cannot create this report anymore. For the next time I will be using a different emergency system (not RAID 0) until I can
> use the main system again when I receive the replacement disk.
Thanks, I'd be so curious to see. Even in the emergency system the report may help - as then I can check OS type / version, Hard Disk Sentinel version, driver version, hard disk model (of the other drive you still have, I suspect it is same model you had previously) etc... which may give ideas what could happen.
> When an error occurs:
> Health + Tray Icon display an Error. Drive Display in Computer shows everything okay - what is wrong.
I can make sure that if the health goes low, the logical drive icon(s) in the Computer reflects this (as soon as Windows updates the display).
> Health + Tray Icon + Drive Display in Computer show error - what is correct.
In some cases, Windows may not update the Drive icon in the Computer immediately, yes, this may require some time.
> Health + Tray Icon display no error. Drive Display in Computer still shows an error - what is wrong again.
Exactly as I wrote before. Windows may requires some more time and/or a manual refresh (F5) to show the changed status.
Re: HDS 4.40 Wrong Data?
What is the problem with it. If you have 1 disk or a RAID 0 array in any case you need a good backup. There is no difference. Don't tell me now that it is more likely that disks may fail. That is correct but that does not mean that if you have a single disk setup it will be more reliable - statistically yes. But you might not be in the middle of the statistic values.Stubi wrote:
So with data transfer problems I might end up again with a bad RAID 0 array without warning. I had this problem already and it was reported by me here in the forum. Not good for me. Intel reports the problem if it gets out of sync with the disks but then it is too late already. I live in a hot and humid climate close to the sea. Oxidation of plugs and resulting contact problems occur very often here.Stubi wrote:I'm not really sure if this would be a good idea ... This may result in invalid / incorrect display of status.
This drive was losing sectors on a daily basis. I contacted Seagate here and they told me that I should send it back. And I sent many disks back to Seagate already (I have a lot of disks and have been using computers for decades) and never got back a bad drive. And luckily I never had a DOA or a bad disk from the beginning. It is not really Seagate - it is an OEM dealer. Perhaps that makes the difference in service?hdsentinel wrote:This is usually better way - as you may even get back a worse (repaired / refurbished) drive in terms of warranty than yours ...
Especially if the drive itself is not as bad as you'd feel, for example the "Uncorrectable error" is originally independent from the drive.
I tested this several times but there was no update at my system even after hours and even with F5. Only if I restarted HDS then it was displayed correctly.hdsentinel wrote: > When an error occurs:
> Health + Tray Icon display an Error. Drive Display in Computer shows everything okay - what is wrong.
I can make sure that if the health goes low, the logical drive icon(s) in the Computer reflects this (as soon as Windows updates the display).
> Health + Tray Icon + Drive Display in Computer show error - what is correct.
In some cases, Windows may not update the Drive icon in the Computer immediately, yes, this may require some time.
> Health + Tray Icon display no error. Drive Display in Computer still shows an error - what is wrong again.
Exactly as I wrote before. Windows may requires some more time and/or a manual refresh (F5) to show the changed status.
I have 3 tray icons showing the health. But often they disappear all but one (they are shown in this tray notification area popup then). I guess this happens when I switch on offline disks but I did not check so much when. So I do not see in the tray a warning anymore if not by accident the icon of the bad disk is shown there. I cannot look without the other computer at HDS. But perhaps there is a different kind of notification possible at HDS (not only the sound - if I am not there at this moment I will not hear it). For instance a big popup by HDS telling me about health problems?
On this emergency system that I am using now there is no HDS. But for the other system it is Windows 7 32 Bit Ultimate with all updates and it is a Seagate 1 TB ST31000528AS and HDS 4.40. The Intel RAID driver is 11.2.0.1006 (I had higher drivers installed for some time but this fits best to the Intel RAID ROM of my BIOS). Board is a Gigabyte GA P55-UD6 with no overclock at all and no HW problems apart from this disk now. In this RAID 0 array there are only Seagate 1 TB ST31000528AS. Apart from other disks there are 3 more Seagate 1 TB ST31000528AS mostly offline. They did not have the offset problems. I did not check all the other mostly offline disks.hdsentinel wrote:Thanks, I'd be so curious to see. Even in the emergency system the report may help - as then I can check OS type / version, Hard Disk Sentinel version, driver version, hard disk model (of the other drive you still have, I suspect it is same model you had previously) etc... which may give ideas what could happen.
-
hdsentinel
- Site Admin
- Posts: 3175
- Joined: 2008.07.27. 17:00
- Location: Hungary
- Contact:
Re: HDS 4.40 Wrong Data?
> What is the problem with it. If you have 1 disk or a RAID 0 array in any case you need a good backup. There is no difference.
> Don't tell me now that it is more likely that disks may fail. That is correct but that does not mean that if you have a
> single disk setup it will be more reliable - statistically yes. But you might not be in the middle of the statistic values.
Yes, if you have full backup, then there should be no problems.
Yes, I agree that the statistical difference does not help when a drive stops working....
> So with data transfer problems I might end up again with a bad RAID 0 array without warning.
> I had this problem already and it was reported by me here in the forum. Not good for me.
> Intel reports the problem if it gets out of sync with the disks but then it is too late already.
> I live in a hot and humid climate close to the sea. Oxidation of plugs and resulting contact problems occur very often here.
Generally, the data transfer / communication errors reported by Hard Disk Sentinel.
These are usually related to other attributes (for example but not limited to the 199 Ultra ATA CRC Error Count).
They appear on the "'Log" page of the hard disk and of course it is possible to configure alert when a such new log entry is added (see Configuration -> Alerts) to be notified about it.
On some models, other attributes may indicate such problems, this is why the developer report would be useful just to check the actual disk model, firmware version, attribute(s). I know this is not possible at this time, so I don't write again
> It is not really Seagate - it is an OEM dealer. Perhaps that makes the difference in service?
Yes, it's possible.
According the experiences OEM dealers as they order hard disks in packages and to integrate in good, quality, OEM PCs usually receive slightly better drives than the ones you may get in simple PC shops.
> I tested this several times but there was no update at my system even after hours and even with F5. Only if I restarted HDS then it was displayed correctly.
Thanks for your attention. Sorry, then I need to write again: the developer report may help to check why this working differently on your system, as Hard Disk Sentinel sets the changed image properly, so I wonder why Windows did not update the display before restart.
> I have 3 tray icons showing the health. But often they disappear all but one (they are shown in this tray notification area popup then).
Yes, Windows automatically hides tray icons when it thinks they're not required to be displayed ...
Maybe a good option to enable showing all icons on the tray area.
Or if it's not possible, there are other methods to show the status information (eg. on the Desktop, by sidebar gadget, etc.)
> But perhaps there is a different kind of notification possible at HDS (not only the sound - if I am not there at this moment I will not hear it).
> For instance a big popup by HDS telling me about health problems?
Of course that is available: just open Configuration -> Message Settings.
There you can control if you prefer to have any combination of e-mail / network message (only XP and previously) / popup message.
On Configuration -> Alerts page, enable the "Send/display message" for any event you prefer to be notified this way (for example the "when a new log entry is added", so then Hard Disk Sentinel will send e-mail (if enabled) and display the message on the screen (if enabled).
> Don't tell me now that it is more likely that disks may fail. That is correct but that does not mean that if you have a
> single disk setup it will be more reliable - statistically yes. But you might not be in the middle of the statistic values.
Yes, if you have full backup, then there should be no problems.
Yes, I agree that the statistical difference does not help when a drive stops working....
> So with data transfer problems I might end up again with a bad RAID 0 array without warning.
> I had this problem already and it was reported by me here in the forum. Not good for me.
> Intel reports the problem if it gets out of sync with the disks but then it is too late already.
> I live in a hot and humid climate close to the sea. Oxidation of plugs and resulting contact problems occur very often here.
Generally, the data transfer / communication errors reported by Hard Disk Sentinel.
These are usually related to other attributes (for example but not limited to the 199 Ultra ATA CRC Error Count).
They appear on the "'Log" page of the hard disk and of course it is possible to configure alert when a such new log entry is added (see Configuration -> Alerts) to be notified about it.
On some models, other attributes may indicate such problems, this is why the developer report would be useful just to check the actual disk model, firmware version, attribute(s). I know this is not possible at this time, so I don't write again
> It is not really Seagate - it is an OEM dealer. Perhaps that makes the difference in service?
Yes, it's possible.
According the experiences OEM dealers as they order hard disks in packages and to integrate in good, quality, OEM PCs usually receive slightly better drives than the ones you may get in simple PC shops.
> I tested this several times but there was no update at my system even after hours and even with F5. Only if I restarted HDS then it was displayed correctly.
Thanks for your attention. Sorry, then I need to write again: the developer report may help to check why this working differently on your system, as Hard Disk Sentinel sets the changed image properly, so I wonder why Windows did not update the display before restart.
> I have 3 tray icons showing the health. But often they disappear all but one (they are shown in this tray notification area popup then).
Yes, Windows automatically hides tray icons when it thinks they're not required to be displayed ...
Maybe a good option to enable showing all icons on the tray area.
Or if it's not possible, there are other methods to show the status information (eg. on the Desktop, by sidebar gadget, etc.)
> But perhaps there is a different kind of notification possible at HDS (not only the sound - if I am not there at this moment I will not hear it).
> For instance a big popup by HDS telling me about health problems?
Of course that is available: just open Configuration -> Message Settings.
There you can control if you prefer to have any combination of e-mail / network message (only XP and previously) / popup message.
On Configuration -> Alerts page, enable the "Send/display message" for any event you prefer to be notified this way (for example the "when a new log entry is added", so then Hard Disk Sentinel will send e-mail (if enabled) and display the message on the screen (if enabled).
Re: HDS 4.40 Wrong Data?
I need a warning when I have Ultra ATA CRC Error Counts and Command Timeouts. This is very important at my system. Reallocated Sectors for instance mostly do not create a bigger problem for a while but a RAID 0 out of sync because of transfer errors does. This can/will make the whole array useless. And to my HW - again the disk in this case is a Seagate 1 TB ST31000528AS (it is sold in huge quantities) and the firmware of this disk was CC38. And there is no warning and no log entry if a value changes that is not marked with the green circle by your developers. Not at this disk or at any other model of disk I have.hdsentinel wrote:Generally, the data transfer / communication errors reported by Hard Disk Sentinel.
These are usually related to other attributes (for example but not limited to the 199 Ultra ATA CRC Error Count).
They appear on the "'Log" page of the hard disk and of course it is possible to configure alert when a such new log entry is added (see Configuration -> Alerts) to be notified about it.
On some models, other attributes may indicate such problems, this is why the developer report would be useful just to check the actual disk model, firmware version, attribute(s). I know this is not possible at this time, so I don't write again
Since I cannot get a warning for such other entries I wanted to write a program that reads such entries from a log file - but I could not find any log data for such S.M.A.R.T. values - only for the green circle values. Therefore now I am even thinking to write my own S.M.A.R.T. tool where I can select the values that are important to me (don't worry - I have been in the IT-Business for about 40 years and worked many years in the development area of one of the biggest software companies in the world. Still have good connections that can help if I would need it for such a software project). If I find the motivation and time I will do it. For me HDS does not cover the data transfer section and problems there. You say it does but it does not at my system - at least not with warnings or log entries. Honestly I give up. I have to find/create a different solution that gives me early warnings for such problems too.
-
hdsentinel
- Site Admin
- Posts: 3175
- Joined: 2008.07.27. 17:00
- Location: Hungary
- Contact:
Re: HDS 4.40 Wrong Data?
> I need a warning when I have Ultra ATA CRC Error Counts and Command Timeouts.
> This is very important at my system.
I can make sure that the newest version 4.40 saves log entries (and alerts) upon Ultra ATA CRC Error count.
Please check on this image:
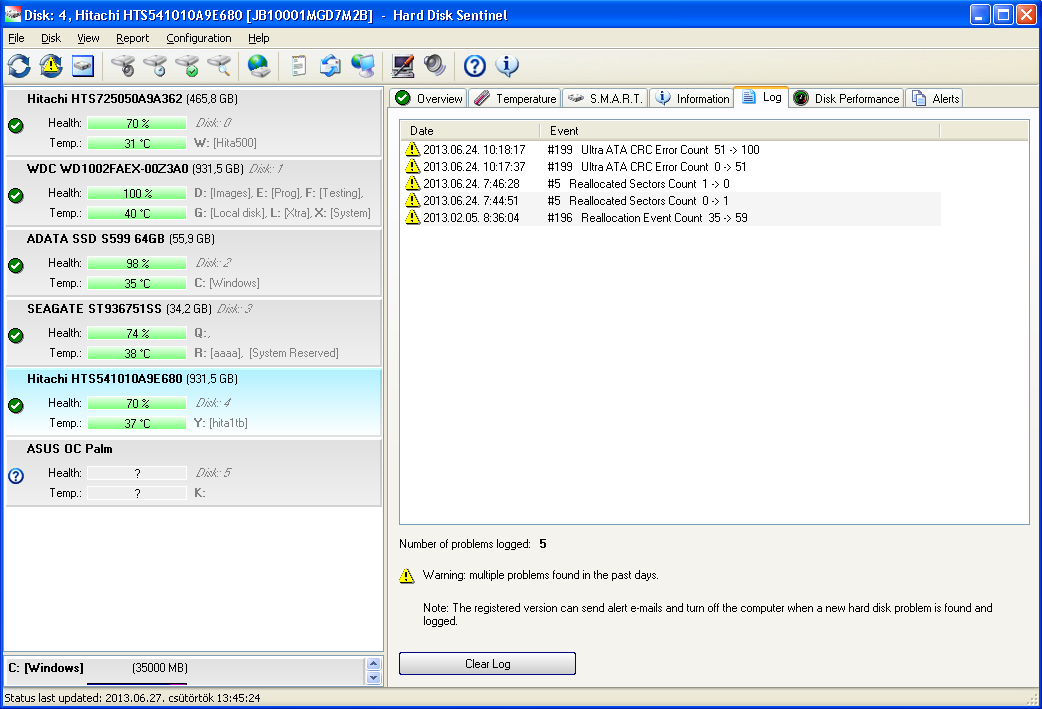
Because of the the experiences with the Command Timeout errors, I can make sure they will be added to the log and (if alerts enabled) it will trigger alert as well. If you prefer, I can send the updated version with this function as soon as possible to help your work.
> Since I cannot get a warning for such other entries I wanted to write a program that reads such entries from a log file - but I could
> not find any log data for such S.M.A.R.T. values - only for the green circle values.
Sorry to disagree - but it is not true, at least in the latest version.
Of course you can any time create a such custom tool.
Maybe you can use the existing features, for example the Configuration -> Advanced options -> Generate and update XML file.
This is designed _exactly_ to automatically export the latest detect values, all information, logs, etc... to XML file.
This can be processed by any third party tool(s) so you can immediately create custom tool to show custom alerts on any change of any value.
Sorry for the problems and troubles - I can confirm your experiences helps the improvement of the software, so I hope the updated version will cover your requirements.
> This is very important at my system.
I can make sure that the newest version 4.40 saves log entries (and alerts) upon Ultra ATA CRC Error count.
Please check on this image:
Because of the the experiences with the Command Timeout errors, I can make sure they will be added to the log and (if alerts enabled) it will trigger alert as well. If you prefer, I can send the updated version with this function as soon as possible to help your work.
> Since I cannot get a warning for such other entries I wanted to write a program that reads such entries from a log file - but I could
> not find any log data for such S.M.A.R.T. values - only for the green circle values.
Sorry to disagree - but it is not true, at least in the latest version.
Of course you can any time create a such custom tool.
Maybe you can use the existing features, for example the Configuration -> Advanced options -> Generate and update XML file.
This is designed _exactly_ to automatically export the latest detect values, all information, logs, etc... to XML file.
This can be processed by any third party tool(s) so you can immediately create custom tool to show custom alerts on any change of any value.
Sorry for the problems and troubles - I can confirm your experiences helps the improvement of the software, so I hope the updated version will cover your requirements.
Re: HDS 4.40 Wrong Data?
I cannot change it. I have the latest version 4.40 and here a change in this attribute did not alert or create any log entries at any disk model I have. And I tried very hard because this attribute is very important to me. If I look at my experience with HDS and your experience with HDS I have the feeling already that we are not talking about the same softwarehdsentinel wrote:I can make sure that the newest version 4.40 saves log entries (and alerts) upon Ultra ATA CRC Error count.
It would be great if the user could select the attributes that should trigger an alarm + log entry. There could be a flag in the settings (call it Expert Mode) and let it run for all others that do not set this flag how it works today. And in expert mode you have a further column in the S.M.A.R.T. report like now "Enable". There you can select if you want an alert + log entry for an attribute change if you want - for ANY attribute (of course not all make sense like start/stop count for instance but then you will not select them). So the user would have ALL options of control and this for whatever model of HD/SSD. And an error message in this case could be simple. An expert does not need a Health Percentage that is questionable anyway. Just write in expert mode in this health report that there was a value change and that the user should check the S.M.A.R.T. report. This is enough information for an expert.hdsentinel wrote: Sorry for the problems and troubles - I can confirm your experiences helps the improvement of the software, so I hope the updated version will cover your requirements.
In respect of warnings - I cannot test it now. A big pop-up would be great. The desktop is often covered by applications. I am not sure if the board speaker warning at HDS works at Win 7. I need it for a different software and so I modified my Windows 7 in this respect. If it does not work and you need it a hint for others: replace the existing beep.sys with a beep.sys from Win XP. This works for the Win 7 32 Bit version but not for Win 7 64 Bit.
Anyhow. If my ideas would come true a dream would come true. And I need more control. I have perfect backups. I do not want to go in detail but my system setup is very complex. So despite the backups it takes me a full day to rebuild it if I lose the RAID array. And on top of it it is extremely annoying work.
Best Regards & Thank You,
Peter
Re: HDS 4.40 Wrong Data?
Just want to add something to the Ultra ATA CRC Error Count problem. I just tested at a PC of a friend of mine - he has HDS running. It seems to be like this:
There are attributes like Reallocated Sectors Count or Current Pending Sectors Count. If you set there an offset of 1 so that the data value is not 0 anymore but 1 you get a warning and a log entry. But this does not work for the Ultra ATA CRC Error Count the same way. Here the offset (or better the data value) has to be higher that you get a warning and log entry - at least at his system. But it was not that easy. Sometimes the trigger value was for instance at the same disk 49 then 50 then 51 then 54, so changing (tested by increasing the offset value with the + sign). But it was in this range. I could not test more because he did not have time. But anyhow - this explains our different experience with this attribute. So for this attribute there is really an alert and log entry at least if the value is high enough to trigger it. I tested with lower values.
There are attributes like Reallocated Sectors Count or Current Pending Sectors Count. If you set there an offset of 1 so that the data value is not 0 anymore but 1 you get a warning and a log entry. But this does not work for the Ultra ATA CRC Error Count the same way. Here the offset (or better the data value) has to be higher that you get a warning and log entry - at least at his system. But it was not that easy. Sometimes the trigger value was for instance at the same disk 49 then 50 then 51 then 54, so changing (tested by increasing the offset value with the + sign). But it was in this range. I could not test more because he did not have time. But anyhow - this explains our different experience with this attribute. So for this attribute there is really an alert and log entry at least if the value is high enough to trigger it. I tested with lower values.
-
hdsentinel
- Site Admin
- Posts: 3175
- Joined: 2008.07.27. 17:00
- Location: Hungary
- Contact:
Re: HDS 4.40 Wrong Data?
> It would be great if the user could select the attributes that should trigger an alarm + log entry.
Yes - then experienced users can control which changes they prefer to be logged / alerted.
As you know (regarding the previous years) your ideas, thoughts are valuable and helped to improve the software, so you can be sure that such improvements will be available.
> Just write in expert mode in this health report that there was a value change and that the user
> should check the S.M.A.R.T. report. This is enough information for an expert.
I can confirm that these settings / expert mode notifications should never affect the displayed health, but can control which changes will be logged (and thus triggering alert if the appropriate alert is enabled).
> A big pop-up would be great. The desktop is often covered by applications.
It is available and displayed "on top" on all windows (system modal).
Just enable
- Configuration -> Alerts -> When a new log entry added -> Send/display message
- Configuration -> Message settings -> Display message on screen
(and maybe disable the e-mail option if you prefer to not have e-mail, just message on the screen).
> I am not sure if the board speaker warning at HDS works at Win 7. I need it for a different software and so I modified my Windows 7 in this respect.
> If it does not work and you need it a hint for others: replace the existing beep.sys with a beep.sys from Win XP.
> This works for the Win 7 32 Bit version but not for Win 7 64 Bit.
In theory, things should work of course. You may configure audio file to be used with the sound card - but also you can specify option to use PC speaker (beeper). These can be set at Configuration -> Alerts where you can use the Test Sound Alert button to verify how things work.
Yes - then experienced users can control which changes they prefer to be logged / alerted.
As you know (regarding the previous years) your ideas, thoughts are valuable and helped to improve the software, so you can be sure that such improvements will be available.
> Just write in expert mode in this health report that there was a value change and that the user
> should check the S.M.A.R.T. report. This is enough information for an expert.
I can confirm that these settings / expert mode notifications should never affect the displayed health, but can control which changes will be logged (and thus triggering alert if the appropriate alert is enabled).
> A big pop-up would be great. The desktop is often covered by applications.
It is available and displayed "on top" on all windows (system modal).
Just enable
- Configuration -> Alerts -> When a new log entry added -> Send/display message
- Configuration -> Message settings -> Display message on screen
(and maybe disable the e-mail option if you prefer to not have e-mail, just message on the screen).
> I am not sure if the board speaker warning at HDS works at Win 7. I need it for a different software and so I modified my Windows 7 in this respect.
> If it does not work and you need it a hint for others: replace the existing beep.sys with a beep.sys from Win XP.
> This works for the Win 7 32 Bit version but not for Win 7 64 Bit.
In theory, things should work of course. You may configure audio file to be used with the sound card - but also you can specify option to use PC speaker (beeper). These can be set at Configuration -> Alerts where you can use the Test Sound Alert button to verify how things work.
-
hdsentinel
- Site Admin
- Posts: 3175
- Joined: 2008.07.27. 17:00
- Location: Hungary
- Contact:
Re: HDS 4.40 Wrong Data?
I can make sure things are a bit more complicated than they appear on the first sight...
According the manual checking (and automatic processing) of 10000's of hard disk reports, there are special patterns defined which may indicate problems.
For example, yes, as you can see, some attributes (generally, but not limited to the critical ones, marked on the S.M.A.R.T. page) immediately trigger the logging and reporting that there is an error with them.
However, some special attributes may require more change (or a change together with other attributes) to trigger such log entry / reported problems.
This is especially because in most cases minor problems _alone_ with these attributes are not critical in the life of the hard disk drive.
I agree that experienced users may prefer to control how these things work - and I can make sure it will be available.
According the manual checking (and automatic processing) of 10000's of hard disk reports, there are special patterns defined which may indicate problems.
For example, yes, as you can see, some attributes (generally, but not limited to the critical ones, marked on the S.M.A.R.T. page) immediately trigger the logging and reporting that there is an error with them.
However, some special attributes may require more change (or a change together with other attributes) to trigger such log entry / reported problems.
This is especially because in most cases minor problems _alone_ with these attributes are not critical in the life of the hard disk drive.
I agree that experienced users may prefer to control how these things work - and I can make sure it will be available.
Re: HDS 4.40 Wrong Data?
Thank you very much for your response.
I was not brave enough to write about my whole dream. But I just want to tell you about it. It might be bigger coding effort but perhaps it might be possible one day.
It would be great if an Expert User (and only this) could set a trigger value. If the attribute data value is bigger or smaller than this trigger value (customizing for instance with "<",">" in front of this trigger value) only then an alert should be triggered. Customizing should be in the SMART report like the offset. So not every value change would trigger an alert. But again - even if every value change at a flagged attribute triggers an alert this would be very helpful already.
But thank you for your great support. I guess there is no disk monitoring software that I did not check. But this I have to say - HDS is still the best of all. Many of the others cannot even handle RAID.
Peter
I was not brave enough to write about my whole dream. But I just want to tell you about it. It might be bigger coding effort but perhaps it might be possible one day.
It would be great if an Expert User (and only this) could set a trigger value. If the attribute data value is bigger or smaller than this trigger value (customizing for instance with "<",">" in front of this trigger value) only then an alert should be triggered. Customizing should be in the SMART report like the offset. So not every value change would trigger an alert. But again - even if every value change at a flagged attribute triggers an alert this would be very helpful already.
But thank you for your great support. I guess there is no disk monitoring software that I did not check. But this I have to say - HDS is still the best of all. Many of the others cannot even handle RAID.
Peter
-
hdsentinel
- Site Admin
- Posts: 3175
- Joined: 2008.07.27. 17:00
- Location: Hungary
- Contact:
Re: HDS 4.40 Wrong Data?
Thanks for the tip and suggestion, yes, to be honest I was thinking exactly about this: that the best would be to allow configuration specific limits when the logging should start.
I suspect this is how the new feature will work, as then it is possible to customize when you prefer to have custom alerts / events to be logged
Thanks for your kind words!
I suspect this is how the new feature will work, as then it is possible to customize when you prefer to have custom alerts / events to be logged
Thanks for your kind words!